
GitHub: https://github.com/robertaitch/telegram-scraper
What's New in v2.0 🎉
Major Performance Improvements:
- 5-10x faster scraping with batch database operations
- 3x faster media downloads with parallel processing (up to 3 concurrent downloads)
- 10-20x faster database operations through connection pooling and batch insertions
- Memory-efficient exports that handle large datasets without running out of memory
- Enhanced progress reporting with actual message counts and percentages
New Features:
- Message count display in channel view
- Configurable download concurrency (adjustable in code)
- Better error handling with exponential backoff retry mechanism
- Optimized database structure with indexes for faster queries
- Object-oriented design for better code maintainability
Technical Improvements:
- Database connection pooling
- Batch message insertions (100 messages per batch)
- Streaming exports for large datasets
- Improved flood control handling
- Periodic state saving (every 50 messages)
Features 🚀
- Scrape messages from multiple Telegram channels
- Download media files (photos, documents) with parallel processing
- Real-time continuous scraping
- Export data to JSON and CSV formats
- SQLite database storage with optimized performance
- Resume capability (saves progress)
- Media reprocessing for failed downloads
- Enhanced progress tracking with message counts
- Interactive menu interface
Prerequisites 📋
Before running the script, you'll need:
- Python 3.7 or higher
- Telegram account
- API credentials from Telegram
Required Python packages
pip install -r requirements.txt
Contents of requirements.txt:
telethon
aiohttp
asyncio
Getting Telegram API Credentials 🔑
- Visit https://my.telegram.org/auth
- Log in with your phone number
- Click on "API development tools"
- Fill in the form:
- App title: Your app name
- Short name: Your app short name
- Platform: Can be left as "Desktop"
- Description: Brief description of your app
- Click "Create application"
- You'll receive:
api_id: A numberapi_hash: A string of letters and numbers
Keep these credentials safe, you'll need them to run the script!
Setup and Running 🔧
- Clone the repository:
git clone https://github.com/robertaitch/telegram-scraper.git
cd telegram-scraper
- Install requirements:
pip install -r requirements.txt
- Run the script:
python telegram-scraper.py
- On first run, you'll be prompted to enter:
- Your API ID
- Your API Hash
- Your phone number (with country code)
- Your phone number (with country code) or bot, but use the phone number option when prompted second time.
- Verification code (sent to your Telegram)
Initial Scraping Behavior 🕒
When scraping a channel for the first time, please note:
- The script will attempt to retrieve the entire channel history, starting from the oldest messages
- Significantly faster than previous versions due to batch processing and parallel downloads
- Initial scraping time depends on:
- The total number of messages in the channel
- Whether media downloading is enabled
- The size and number of media files
- Your internet connection speed
- Telegram's rate limiting
- The script uses pagination and maintains state, so if interrupted, it can resume from where it left off
- Enhanced progress display shows actual message counts (e.g., "1,500/10,000 messages")
- Messages are stored in the database in batches for optimal performance
- Media downloads run in parallel (up to 3 simultaneous downloads) for faster processing
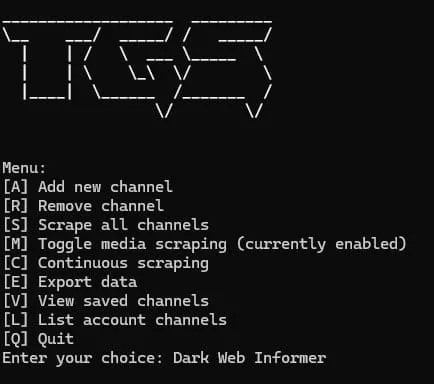
Usage 📝
The script provides an interactive menu with the following options:
- [A] Add new channel
- Enter the channel ID or channelname
- [R] Remove channel
- Remove a channel from scraping list
- [S] Scrape all channels
- One-time scraping of all configured channels
- [M] Toggle media scraping
- Enable/disable downloading of media files
- [C] Continuous scraping
- Real-time monitoring of channels for new messages
- [E] Export data
- Export to JSON and CSV formats (memory-efficient for large datasets)
- [V] View saved channels
- List all saved channels with message counts
- [L] List account channels
- List all channels with ID:s for account
- [Q] Quit
Channel IDs 📢
You can use either:
- Channel username (e.g.,
channelname) - Channel ID (e.g.,
-1001234567890)
Data Storage 💾
Database Structure
Data is stored in SQLite databases, one per channel with optimized indexes:
- Location:
./channelname/channelname.db - Table:
messagesid: Primary keymessage_id: Telegram message ID (indexed)date: Message timestamp (indexed)sender_id: Sender's Telegram IDfirst_name: Sender's first namelast_name: Sender's last nameusername: Sender's usernamemessage: Message textmedia_type: Type of media (if any)media_path: Local path to downloaded mediareply_to: ID of replied message (if any)
Media Storage 📁
Media files are stored in:
- Location:
./channelname/media/ - Files are named using message ID or original filename
- Parallel downloads for faster media acquisition
Exported Data 📊
Data can be exported in two formats with memory-efficient processing:
- CSV:
./channelname/channelname.csv- Human-readable spreadsheet format
- Easy to import into Excel/Google Sheets
- Streaming export handles large datasets
- JSON:
./channelname/channelname.json- Structured data format
- Ideal for programmatic processing
- Memory-optimized for large files
Performance Tuning ⚙️
You can adjust these performance settings in the code:
max_concurrent_downloads = 3: Number of simultaneous media downloadsbatch_size = 100: Number of messages processed in each batchstate_save_interval = 50: How often to save progress
Features in Detail 🔍
Continuous Scraping
The continuous scraping feature ([C] option) allows you to:
- Monitor channels in real-time
- Automatically download new messages
- Download media as it's posted with parallel processing
- Run indefinitely until interrupted (Ctrl+C)
- Maintains state between runs
Media Handling
The script can download:
- Photos
- Documents
- Other media types supported by Telegram
- Parallel downloads for faster processing
- Improved retry mechanism with exponential backoff
- Skips existing files to avoid duplicates
Error Handling 🛠️
The script includes:
- Enhanced retry mechanism with exponential backoff for failed media downloads
- State preservation in case of interruption
- Improved flood control compliance
- Comprehensive error logging for failed operations
- Better rate limit handling with automatic waiting
Limitations ⚠️
- Respects Telegram's rate limits
- Can only access public channels or channels you're a member of
- Media download size limits apply as per Telegram's restrictions
Contributing 🤝
Contributions are welcome! Please feel free to submit a Pull Request.
License 📄
This project is licensed under the MIT License - see the LICENSE file for details.
Disclaimer ⚖️
This tool is for educational purposes only. Make sure to:
- Respect Telegram's Terms of Service
- Obtain necessary permissions before scraping
- Use responsibly and ethically
- Comply with data protection regulations




{kind=link}