
GitHub Link: https://github.com/snooppr/snoop/blob/master/README.en.md
Snoop Project Overview:
- Purpose: Snoop is designed to help organizations process large amounts of documents, often in the context of investigative journalism, research, or legal work. It provides a framework for the collection, processing, and searching of documents at scale.
- Key Features:
- Document Ingestion: The platform can ingest documents from various sources, such as file systems, email inboxes, and web pages.
- Processing Pipelines: Snoop uses pipelines to process documents, which can include tasks like OCR (Optical Character Recognition), metadata extraction, and text extraction from PDFs or images.
- Search and Indexing: The processed documents are indexed, allowing for powerful search capabilities across large datasets.
- APIs: Snoop provides APIs that allow developers to interact with the system programmatically, making it easier to integrate into other tools or workflows.
- Use Cases:
- The platform is especially useful in environments where there is a need to handle large volumes of unstructured data, such as in investigative journalism projects, legal discovery, or research projects requiring deep document analysis.
- Deployment: The project can be deployed on various environments, and it is designed to scale according to the needs of the users.
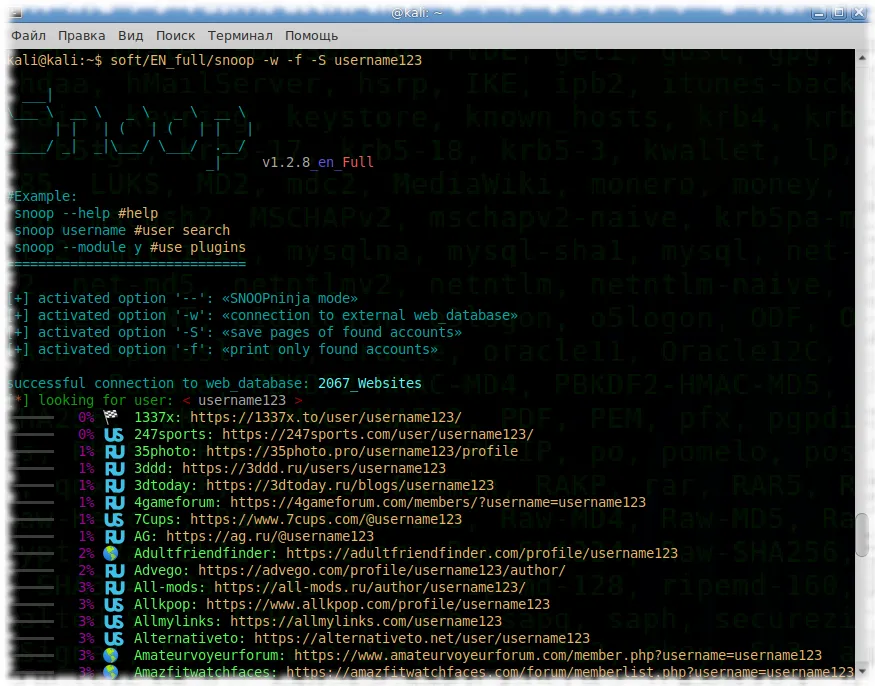
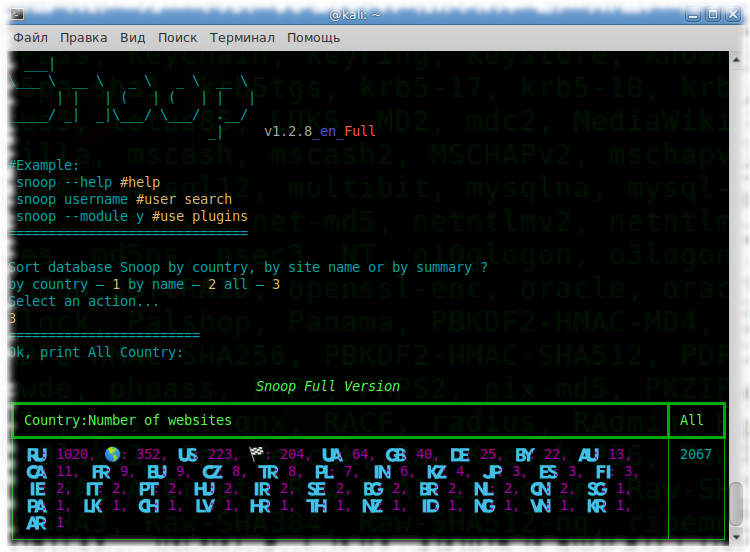
Snoop for OS Windows and GNU/Linux
Snoop Local database




{kind=link}