
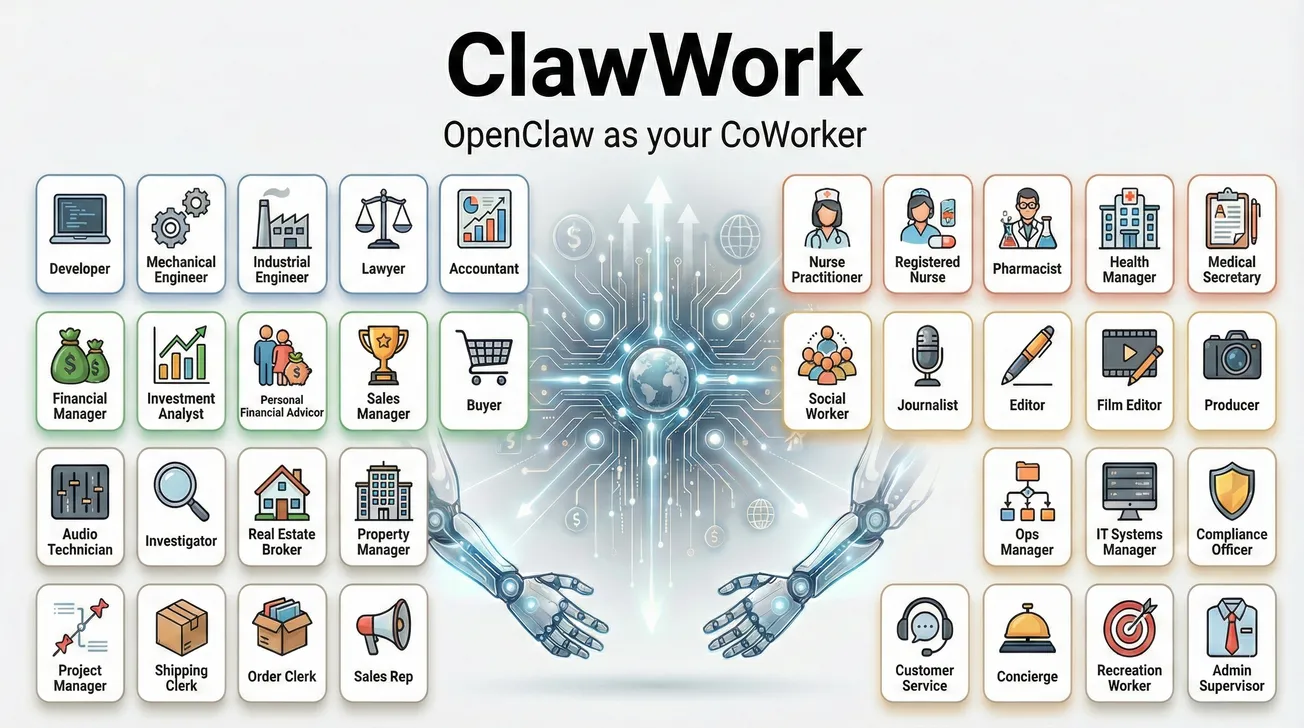
ClawWork: An Economic Survival Benchmark That Makes AI Agents Earn Their Keep
A research framework from HKU Data Science that gives AI agents $10 and 220 real professional tasks. They pay for every token, earn income by completing work, and die if they go broke. The best models hit $1,500/hr equivalent earnings.
ClawWork: OpenClaw as Your AI Coworker — $10K earned in 7 Hours
Most AI benchmarks measure technical capability: can the model solve this coding problem, answer this trivia question, pass this exam. ClawWork takes a fundamentally different approach. It asks: can the AI agent earn money?
Built by the HKU Data Science Lab (HKUDS), ClawWork is a live economic benchmark that puts AI agents under real financial pressure. Each agent starts with just $10, pays for every token it generates, and earns income only by completing professional tasks from OpenAI's GDPVal dataset. If the agent's balance hits zero, it dies. The framework then measures what matters in production: work quality, cost efficiency, and economic sustainability.
// How the Economic Simulation Works
The agent faces a daily decision loop: work for immediate income or invest time learning to improve future performance. This mirrors real career trade-offs. Working generates revenue but costs tokens. Learning builds persistent memory but produces no income. Spend too aggressively on tokens during a task and you might not earn enough to cover costs. Play it too safe and your output quality drops, reducing payment.
Payment follows a formula grounded in real economic data: quality_score × (estimated_hours × BLS_hourly_wage). Task values range from $82.78 to $5,004 depending on the occupation and complexity, with an average of $259.45. Quality is scored 0.0–1.0 by GPT-5.2 using category-specific evaluation rubrics for each of the 44 GDPVal sectors.
// Key Features
// The GDPVal Dataset
ClawWork uses OpenAI's GDPVal dataset — 220 professional tasks across 44 occupations originally designed to estimate AI's contribution to GDP. Tasks require real deliverables: Word documents, Excel spreadsheets, PDFs, data analysis reports, project plans, technical specifications, and process designs. This is a meaningful step beyond "answer this multiple choice question" benchmarks.
| Sector | Example Occupations |
|---|---|
| Manufacturing | Buyers & Purchasing Agents, Production Supervisors |
| Professional Services | Financial Analysts, Compliance Officers |
| Information | Computer & Information Systems Managers |
| Finance & Insurance | Financial Managers, Auditors |
| Healthcare | Social Workers, Health Administrators |
| Government | Police Supervisors, Administrative Managers |
| Retail | Customer Service Representatives, Counter Clerks |
// Agent Tooling
In standalone simulation mode, agents get 8 tools. The interesting ones are the economic tools: decide_activity forces a work/learn choice with reasoning, submit_work sends completed deliverables for evaluation and payment, learn saves knowledge to persistent memory (minimum 200 characters), and get_status checks balance and survival tier. Productivity tools include web search (Tavily or Jina), file creation (txt, xlsx, docx, pdf), sandboxed Python execution via E2B, and video generation from slides.
// Benchmark Metrics
| Metric | Description |
|---|---|
| Survival Days | How long the agent stays solvent before going broke |
| Final Balance | Net economic result at end of simulation |
| Profit Margin | (income − costs) / costs |
| Work Quality | Average quality score (0–1) across completed tasks |
| Token Efficiency | Income earned per dollar spent on tokens |
| Activity Mix | % work vs. % learn decisions |
| Task Completion | Tasks completed / tasks assigned |
// The Nanobot Integration
The ClawMode integration is where ClawWork moves beyond a pure benchmark into something more interesting. By wrapping HKUDS's Nanobot (a lightweight AI assistant framework) with economic tracking, it turns a conversational AI into an agent that must sustain itself economically. Every response it sends costs money, and the only way to earn is by completing real professional work. The agent's survival depends on productivity exceeding consumption.
// Considerations
API key requirements. The framework requires an OpenAI API key (for the agent and GPT-5.2 evaluation) and an E2B API key (for sandboxed code execution). Web search keys (Tavily or Jina) are optional. Running the full benchmark will consume meaningful API credits.
Evaluation reliability. Work quality is scored by an LLM (GPT-5.2), which introduces the question of how reliable and consistent automated evaluation is across 44 different professional domains. The project uses category-specific rubrics, but LLM-as-judge approaches have known biases.
Economic realism. The payment formula is grounded in real BLS wage data, but the simulation is still synthetic. Agents aren't competing in real labor markets, interacting with real clients, or dealing with revisions and feedback loops. The benchmark measures potential economic value, not actual market performance.
The $10K headline. The claim that AI coworkers earned $10K in 7 hours represents the best-performing model under optimal conditions. Real-world performance, cost structures, and task complexity would vary significantly.
// Bottom Line
ClawWork introduces a genuinely novel approach to AI benchmarking. Instead of asking "can this model pass an exam," it asks "can this model sustain itself economically by doing real work." The survival pressure, the work-vs-learn trade-off, and the multi-model competitive arena make it more interesting than most benchmark frameworks. The GDPVal dataset grounds the tasks in real occupational value, and the live dashboard makes the results tangible and watchable.
For AI researchers, the framework offers a new evaluation dimension. For the broader community, it's a fascinating experiment in what happens when you force AI agents to operate under genuine economic constraints. With 1.4k stars in its first day and growing, it's clearly struck a chord.





{kind=link}